
Rachel Thomson
This workshop (second in the series) focused our attention on the relationship between the front end of the bot (written in Java and creating the interface with the user, designed to hear and decipher their question) and the back end of the bot – the potential answers to the question that takes the form of a data base or archive (and created in python code within a flask container). Workshop leader Suze Shardlow encouraged us to think through all the stages that might be involved in a simple question and answer cycle – each action requiring construction. Here we see one attempt to map the stages involved.
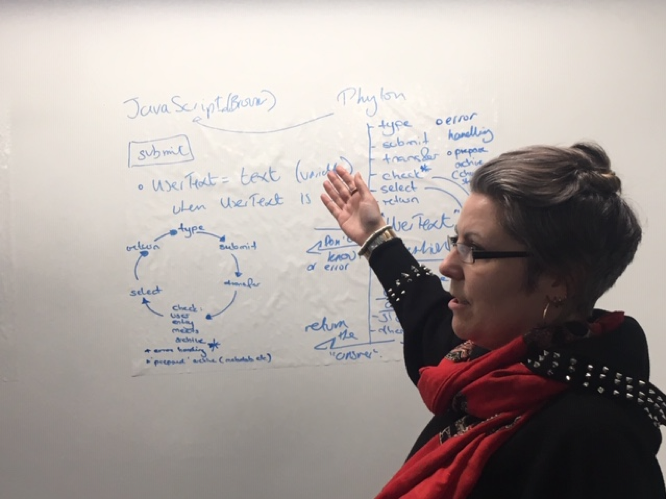
Suze encouraged us to juxtapose a typical commercial application for a chat bot (for example online Pizza ordering) and our attempt to use a chat bot as an interface for an archive made up of interviews conducted in a conversational style. So for example, the question ‘how can I help you’ on a pizza order site is limited in its potential answers to the menu offered by the restaurant. The questions that we might ask the WRAP archive and the kinds of answers that could be evoked are not so constrained. So how do we begin the process of focusing down the kinds of questions that can be asked and the potential answers that can be given?
We could offer our users a limited set of FAQs to choose between. This would make things easier in the short-term, but it would also mean that we miss out on discovering what it is that contemporary audiences want to ask. It would also derail our desire to mimic conversation – to create the feeling that the user is talking directly to Mary and to the past that was so powerful in the first workshop when we first met Mary.
Thinking about potential questions also prompted a discussion about what was feminist about our bot. Would she for example refuse to ask certain questions, suggest that people reflect a bit more or simply suggest that they ‘google’ that one. How censorious and how curious would our chat bot-be?
We also had to think through the relationship between the questions asked through our chat-bot today (which would be relayed to the archive) and the questions asked thirty years ago by researchers. At one level this is an entirely practical matter – perhaps we could simply piggy-back on the original questions, re-using these to call up original answers. The problem with this strategy is that the interviews were highly conversational in style – it can be hard to isolate a single question and answer as we see below in this extract from an interview with Melanie:
Q: How about ways to stop it being sexually transmitted? Do you know how you can not catch it, I mean what safe sex is?
A: Oh yes, using a condom.
Q: Is there anything else that would count as safe sex other than using a condom?
A: No.
Q: Right, I’m not testing you. I’m generally trying to find out what type of things people know.
A: I think this is terrible actually, I really haven’t thought about it and I’m realising that I know so little about it’
Q: For instance would something like oral sex, would you know if it had any risk attached to it or not?
A: Well no I wouldn’t, but I would imagine that I would say it has.
Q: Right. So you’ve got a general idea of how it’s …
A: I’m assuming it has, is that right?
So, if we don’t piggy-back on the old questions, do we simply ignore them? In relation to the above example we might train the chat bot to hear a question that includes the word ‘safe sex’ – how do you understand safe sex? Do you practice safe sex? And we might select this particular extract from Melanie as an answer ‘I think this is terrible actually, I really haven’t thought about it and I’m realising that I know so little about it’. This allows for a direct relationship with the contemporary questioner and Melanie. Alternatively, the original researcher could be treated as an integral part of the conversation. Following this logic our contemporary user might ask a question of the archive along the lines of ‘how was safer sex talked about in the interviews’ – allowing an extract of conversation to count as an answer.
For the members of the workshop, this question linked directly to our explorations of who/ where/ how the feminism of the project sits and the relationship between feminism then (as captured in the approach of feminist researchers), feminism now (as captured by our decisions as to how to engineer the relationship between the front and back end of the bot) but also feminism (?) of the user whose questions have the potential to open the archive up in new ways.
And this takes us to the final key area of our discussion during the workshop which was the relationship between a rule-based design for training our bot to make links between questions and potential answers and a machine learning approach (Artificial Intelligence) approach where the bot works directly with the language of the data set rather than the way that it is coded – having been already trained for the task using rule based approaches that are no longer visible to us. In thinking through these alternative strategies we considered the primary role of the chat-bot as a user-facing tool that would helps people access the archive – rather than a tool for analysis of the archive. In terms of the ambitions of the FACT workshop and the RAD project our aims are relatively modest – to collaboratively build a simple chat-bot and to gain an understanding of the labour involved in this process (FACT), and to experiment with ways of reanimating the data set to encourage new users and to learn about the questions they may have (RAD).
As with the previous workshop we also learned about the painstaking process of coding and that things take much longer than you might think – both in building the front end of the chat-bot and in preparing the data for the back-end. Our immediate plan is to mark up 5 interviews with around 10 key words as a first stage of creating a relationship between possible questions and potential replies. On Saturday March 7th we are introducing our pilot version of the chat-bot to her first audience at an International Women’s Day event at Manchester Central Reference Library where we will showcase some of the ‘reanimation experiments’ that have been part of the RAD project.